4.2. Interacciones conversacionales
En los últimos años, se han popularizado notablemente los dispositivos y aplicaciones conversacionales, especialmente los que se basan en una interacción mediante la voz. De hecho, en 2022, en los Estados Unidos, el número de personas que los usaban al menos una vez al mes era de unos 124 millones, aproximadamente un 45 % de la población.
Estos dispositivos y aplicaciones conversacionales pueden basarse, como decimos, en la voz, pero también en el texto y pueden tomar formas diversas: canales de mensajería, aplicaciones específicas, integración dentro de webs o ser parte de sistemas operativos. Su propósito es llevar a cabo tareas a partir de las órdenes, peticiones o preguntas que les planteamos y su desarrollo está ligado al procesamiento de lenguaje natural y la inteligencia artificial.
Aun así, no todas las interacciones basadas en la conversación, especialmente las que usan texto (chatbots) tienen el mismo grado de relación con la inteligencia artificial. Muchos de estos chatbots se basan en un lenguaje marcado que se llama AIML (Artificial Intelligence Markup Language), que facilita el hecho de estructurar las posibles respuestas utilizando patrones y categorías. Si bien es útil, este lenguaje no permite el razonamiento lógico ni el verdadero aprendizaje, en cambio, otros asistentes por voz más recientes emplean Aprendizaje Profundo (Deep learning), una tecnología basada en redes neuronales que pretende modelar abstracciones a partir de grandes cantidades de datos.
Uno de los primeros programas que fue capaz de procesar lenguaje natural con el propósito de mantener una conversación de texto con la persona usuaria fue Eliza. Este programa informático fue diseñado por el MIT entre el 1964 y el 1966. Funcionaba reconociendo palabras clave que relacionaba con frases ya registradas en su base de datos para dar una respuesta u otra, de manera abierta como lo haría un terapeuta.
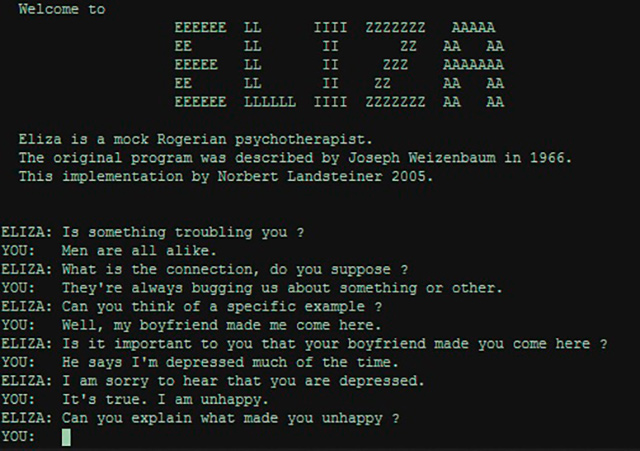
Figura 27. Interfaz del chatbot Eliza (1964-1966)
Fuente: dominio público.
Actualmente, podemos encontrar diferentes implementaciones de Eliza en la red, como por ejemplo la que llevó a cabo Norbert Landsteiner, mass:werk.
Por otro lado, los bots de redes sociales como Twitter o de sistemas de mensajería como Telegram son bastante populares. Integrar bots en este tipo de entornos facilita centrarse en los contenidos y en la vertiente creativa y no específicamente en crear una interfaz, puesto que los chatbots quedarán integrados en las diferentes plataformas, con su propia estética.
La variedad de bots en Twitter es enorme, por ejemplo, @RecuerdameBot sirve para pedir que nos recuerde el tuit que deseemos al cabo de un tiempo concreto; @dreamjobsbot comparte imágenes generadas con inteligencia artificial en respuesta a los trabajos soñados que los diferentes usuarios le hacen llegar, y @MakeItAQuote convierte cualquier tuit en que se le etiquete en una imagen como si fuera una frase de alguien famoso.
También es interesante dedicar atención a la otra vertiente de las interacciones conversacionales, los chatbots que se basan en la voz. Uno de los precedentes en este ámbito es Audrey (1952), un dispositivo de reconocimiento automático de dígitos. La máquina podía entender de cero a nueve dígitos, pero su aspecto tenía poco que ver con los altavoces que se comercializan hoy: ocupaba dos metros de altura. Shoebox, desarrollado diez años después de Audrey, era más pequeño y reconocía dieciséis palabras, además de los dígitos, y seis órdenes de control. A pesar de que se desarrollan, por ejemplo, programas que permiten la conversión de voz en texto, no será hasta el 2010, aproximadamente, que el campo de los asistentes vuelve a generar bastante interés. Es el momento de lanzamiento de Watson de IBM, Siri de Apple, el Asistente de Google, Cortana de Microsoft y Alexa de Amazon. Estos asistentes de voz ya usan el reconocimiento complejo y responden a una variedad amplia de órdenes.

Figura 28. Director de IBM realizando una demostración de Shoebox (1962)
Fuente: web IBM Shoebox.
Eliza, Audrey, Alexa, Cortana… ¿Os habéis fijado que la mayoría de interfaces conversacionales tienen nombres de mujer? Y no solo esto, sino que la mayoría, por defecto, tienen voces que podemos asociar a lo femenino.
Si nos movemos en el ámbito de la ficción, un joven Harrison Ford en Blade runner (1985) interactuaba con un superordenador llamado Esper. Concretamente, en una escena de la película, le pide recorrer y acercar una imagen mediante órdenes de voz. En este caso, no se prescindía de la pantalla, sino que el asistente más bien sustituía al ratón o al teclado. En la película Her, en cambio, el protagonismo no es anecdótico, sino que toda la narración versa sobre el enamoramiento del protagonista hacia un asistente conversacional, en concreto, lleva por nombre Samantha.
Actualmente, el uso de asistentes conversacionales de voz es bastante diferente según los países. Por ejemplo, volviendo a los Estados Unidos, hay todavía un cierto crecimiento, pero sostenido, y la mayoría de personas que usan asistentes de voz es con el móvil y no con altavoces, a pesar de que estos últimos cada vez son más populares.
En cuanto a nuestra interacción con los asistentes de voz, podemos diseccionarla en el flujo siguiente: en primer lugar, nosotros iniciamos la comunicación haciendo una pregunta o diciendo algo, habitualmente mediante lo que se llama wakeword, una palabra o conjunto de palabras que activan el dispositivo o aplicación. Seguidamente, usando el reconocimiento automático del lenguaje (Natural Language Processing, NLP por sus siglas en inglés), son capaces de reconocer las palabras clave y hacer búsquedas a internet (en nuestro correo, por ejemplo) y también en la nube (noticias del día, datos de bolsa…) comparando patrones de otras búsquedas y de nuestras propias acciones previas. Con todos estos contenidos, el asistente toma una decisión sobre qué respuesta darnos, que convierte de texto a voz (text-to-speech).
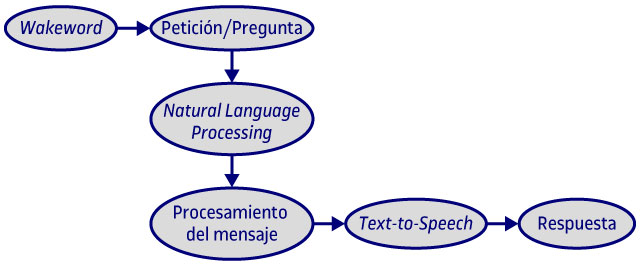
Figura 29. Flujo de interacción conversacional
Fuente: elaboración propia.
Uno de los trabajos artísticos que reflexiona sobre el reconocimiento y el aprendizaje a partir de la voz es Echo (2021), un proyecto de Lua Coderch en colaboración con Julia Múgica, Lluís Nacenta e Iván Paz. Se trata de una escultura de código abierto que solo puede usar palabras que ha oído previamente, palabras que combina para poder hablar y construir frases. El título de la pieza hace referencia al mito de la ninfa Eco, que fue castigada a no poder usar su voz y obligada a repetir la última palabra de la persona con quien tenía una conversación. Cuando está instalada en el espacio expositivo, la invitación a interactuar se hace mediante el uso de un sencillo objeto: un taburete. Es así como entendemos que se nos está invitando como público a sentarnos y contribuir al aprendizaje de Echo. El año 2022, la pieza recibió el premio ARCO/Beep de arte electrónico.
Con Echo el taburete tiene el propósito de facilitar la interacción con el público, pero lo cierto es que cuando miramos un altavoz inteligente, por ejemplo, no tenemos muchas claves para saber qué tenemos que hacer o qué se espera de nosotros. Por eso, a continuación, presentamos una serie de consejos de diseño para Alexa extraídos de la guía de diseño para desarrolladores de Amazon, pero que pueden aplicarse de manera más amplia. Conocer estas indicaciones es útil para poder adaptarlas o, incluso, como hemos visto con Echo, cambiarlas en nuestros propios proyectos artísticos.
Los consejos están agrupados en cuatro grandes bloques:
- Ser adaptable: facilita que los usuarios se expresen con sus palabras.
- Ser personal: individualiza la interacción, crea familiaridad.
- Estar disponible: no te bases en los menús verticales de las interfaces gráficas, muestra las opciones al mismo nivel.
- Ser narrativo: el objetivo es hablar con las personas, no hacia las personas. Por eso, recomiendan variedad en el vocabulario, brevedad y evitar repeticiones innecesarias.
Disponible en: https://developer.amazon.com/en-us/docs/alexa/alexa-design/get-started.html
Otro proyecto que plantea de manera creativa la interacción conversacional es Conversational Implant, una instalación interactiva diseñada por Becoming. El sistema dispone de una interfaz que permite a las personas usuarias mantener una conversación, el marco de la cual gira alrededor de una narración sobre objetos, vegetales y animales como entidades iguales. Las conversaciones escritas son transformadas en voz mediante TTS (Text to Speech) y transmitidas a la planta con el propósito de fortalecerla con voces casi humanas.
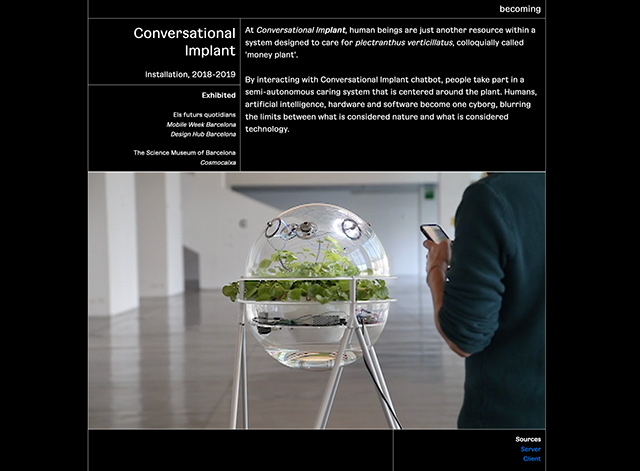
Figura 30. Conversational implant 2018-2019
Fuente: web de los artistas.
Finalmente, hay que comentar que las interfaces de voz han despertado varias inquietudes. Por un lado, nos facilitan el acceso y comunicación sin que tengamos que tocar o hacer clic en una pantalla. Aun así, también afectan cómo y qué información acaban devolviendo, especialmente, en cuanto a los contenidos que obtiene de internet. Cuando nosotros introducimos directamente las búsquedas con texto en la pantalla de un buscador, este último nos suele devolver múltiples resultados ordenados en varias páginas. Si bien está demostrado que la mayoría de usuarios no pasan de la primera página, la posibilidad de consultar otros resultados continúa existiendo. En el caso de las interfaces por voz, se restringe esta opción y nosotros, como personas usuarias, recibimos la información ya seleccionada, como si se tratara de una elección transparente.
Un ámbito adicional de preocupación hacia las interfaces de voz es la capacidad de escucharnos continuamente. En el apartado 3.3 aparecen dos trabajos artísticos, HacKIT, de Rubez Chong, y Project Alias, de Bjørn Karmann. Además de estos proyectos, hay iniciativas de código abierto como Mycroft, que, con un espíritu propositivo, quieren garantizar una buena experiencia sin sacrificar la privacidad de las personas usuarias.