4.2. Interaccions conversacionals
Els darrers anys s’han popularitzat notablement els dispositius i aplicacions conversacionals, especialment els que es basen en una interacció mitjançant la veu. De fet, l’any 2022, als Estats Units, el nombre de persones que els feien servir almenys un cop al mes era d’uns 124 milions, aproximadament un 45 % de la població.
Aquests dispositius i aplicacions conversacionals poden basar-se, com diem, en la veu, però també en el text i poden agafar formes diverses: canals de missatgeria, aplicacions específiques, integració dins de webs o ser part de sistemes operatius. El seu propòsit és dur a terme tasques a partir de les ordres que els donem, peticions o preguntes i el seu desenvolupament està lligat al processament de llenguatge natural i la intel·ligència artificial.
Tot i així, no totes les interaccions basades en la conversa, especialment els que fan servir text (xatbots) tenen el mateix grau de relació amb la intel·ligència artificial. Molts d’aquests xatbots es basen en un llenguatge marcat que s’anomena AIML (Artificial Intelligence Markup Language), que facilita el fet d’estructurar les possibles respostes utilitzant patrons i categories. Si bé és útil, aquest llenguatge no permet el raonament lògic ni el veritable aprenentatge, en canvi, altres assistents per veu més recents empren Aprenentatge Profund (Deep learning), una tecnologia basada en xarxes neuronals que pretén modelar abstraccions a partir de grans quantitats de dades.
Un dels primers programes que va ser capaç de processar llenguatge natural amb el propòsit de mantenir una conversa de text amb la persona usuària va ser Eliza. Aquest programa informàtic va ser dissenyat pel MIT entre el 1964 i el 1966. Funcionava reconeixent paraules clau que relacionava amb frases ja registrades a la seva base de dades per donar una resposta o una altra, de manera oberta com ho faria un terapeuta.
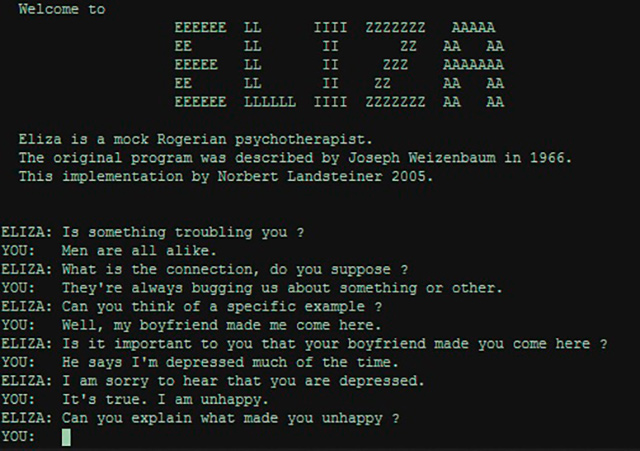
Figura 27. Interfície del xatbot Eliza (1964 – 1966)
Font: domini públic.
Actualment podem trobar diferents implementacions d’Eliza a la xarxa, com per exemple la que va dur a terme Norbert Landsteiner, mass:werk.
D’altra banda, els bots de xarxes socials com Twitter o de sistemes de missatgeria com Telegram són bastant populars. Integrar-los en aquest tipus d’entorns facilita centrar-se en els continguts i en la vessant creativa i no específicament a crear una interfície, ja que els xatbots quedaran integrats en les diferents plataformes, amb la seva pròpia estètica.
La varietat de bots a Twitter és enorme, per exemple, @RecuerdameBot serveix per demanar que ens recordi el tuit que desitgem al cap d’un temps concret; @dreamjobsbot comparteix imatges generades amb intel·ligència artificial en resposta als treballs somiats que els diferents usuaris li fan arribar, i @MakeItAQuote converteix qualsevol tuit en què se l’etiqueti en una imatge com si fos una frase d’algú famós.
També és interessant dedicar atenció a l’altra vessant de les interaccions conversacionals, els xatbots que es basen en la veu. Un dels precedents en aquest àmbit és Audrey (1952), un dispositiu de reconeixement automàtic de dígits. La màquina podia entendre de zero a nou dígits, però el seu aspecte tenia poc a veure amb els altaveus que es comercialitzen avui: ocupava dos metres d’alçada. Shoebox, desenvolupat deu anys després que Audrey, era més petit i reconeixia setze paraules, a més dels dígits, i sis ordres de control. Tot i que es desenvolupen, per exemple, programes que permeten la conversió de veu en text, no serà fins al 2010, aproximadament, que el camp dels assistents torna a generar força interès. És el moment de llançament de Watson d’IBM, Siri d’Apple, l’Assistent de Google, Cortana de Microsoft i Alexa d’Amazon. Aquests assistents de veu ja fan servir el reconeixement complex i responen a una varietat àmplia d’ordres.

Figura 28. Director d’IBM realitzant una demostració de Shoebox (1962)
Font: web d’IBM Shoebox.
Eliza, Audrey, Alexa, Cortana… Us heu fixat, però, que la majoria d’interfícies conversacionals tenen noms de dona? I no només això, sinó que la majoria, per defecte, tenen veus que podem associar al femení?
Si ens movem en l’àmbit de la ficció, un jove Harrison Ford a Blade runner (1985) interactuava amb un superordinador anomenat Esper. Concretament, en una escena de la pel·lícula, li demana recórrer i acostar una imatge mitjançant ordres de veu. En aquest cas, no es prescindia de la pantalla, sinó que l’assistent més aviat substituïa el ratolí o el teclat. A la pel·lícula Her, en canvi, el protagonisme no és anecdòtic, sinó que tota la narració versa sobre l’enamorament del protagonista envers un assistent conversacional, en concret, porta per nom Samantha.
Actualment, l’ús d’assistents conversacionals de veu és força diferent segons els països. Per exemple, tornant als Estats Units, hi ha encara un cert creixement, però sostingut, i la majoria de persones que fan servir assistents de veu és amb el mòbil i no amb altaveus, tot i que aquests últims cada vegada són més populars.
Quant a la nostra interacció amb els assistents de veu, podem disseccionar-la en el flux següent: en primer lloc, nosaltres iniciem la comunicació fent una pregunta o dient alguna cosa, habitualment mitjançant el que s’anomena wakeword, una paraula o conjunt de paraules que activen el dispositiu o aplicació. Seguidament, fent servir el reconeixement automàtic del llenguatge (Natural Language Processing, NLP per les seves sigles en anglès), són capaços de reconèixer les paraules clau i fer cerques a internet (al nostre correu, per exemple) i també al núvol (notícies del dia, dades de borsa…) comparant patrons d’altres cerques i de les nostres pròpies accions prèvies. Amb tots aquests continguts, l’assistent pren una decisió sobre quina resposta donar-nos, que converteix de text a veu (text-to-speech).
Figura 29. Flux d’interacció conversacional
Font: elaboració pròpia.
Un dels treballs artístics que reflexiona sobre el reconeixement i l’aprenentatge a partir de la veu és Echo (2021), un projecte de Lua Coderch en col·laboració amb Julia Múgica, Lluís Nacenta i Iván Paz. Es tracta d’una escultura de codi obert que només pot fer servir paraules que ha sentit prèviament, paraules que combina per poder parlar i construir frases. El títol de la peça fa referència al mite de la nimfa Eco, que va ser castigada a no poder fer servir la seva veu i obligada a repetir l’última paraula de la persona amb qui tenia una conversa. Quan està instal·lada a l’espai expositiu, la invitació a interactuar es fa mitjançant l’ús d’un senzill objecte: un tamboret. És així com entenem que se’ns està convidant com a públic a seure i contribuir a l’aprenentatge d’Echo. L’any 2022, la peça va rebre el premi ARCO/Beep d’art electrònic.
Amb Echo el tamboret té el propòsit de facilitar la interacció amb el públic, però el cert és que quan mirem un altaveu intel·ligent, per exemple, no tenim gaires claus per saber què hem de fer o què s’espera de nosaltres. Per això, a continuació presentem una sèrie de consells de disseny per a Alexa extrets de la guia de disseny per a desenvolupadors d’Amazon, però que poden aplicar-se de manera més àmplia. Conèixer aquestes indicacions és útil per poder adaptar-les o, fins i tot , com hem vist amb Echo, capgirar-les en els nostres propis projectes artístics.
Els consells estan agrupats en quatre grans blocs:
- Sigues adaptable: facilita que els usuaris s’expressin amb les seves paraules.
- Sigues personal: individualitza la interacció, crea familiaritat.
- Estigues disponible: no et basis en els menús verticals de les interfícies gràfiques, mostra les opcions al mateix nivell.
- Sigues narratiu: l’objectiu és parlar amb les persones, no cap a les persones. Per això, recomanen varietat en el vocabulari, brevetat i evitar repeticions innecessàries.
Extret de: https://developer.amazon.com/en-US/docs/alexa/alexa-design/get-started.html
Un altre projecte que planteja de manera creativa la interacció conversacional és Conversational Implant, una instal·lació interactiva dissenyada per Becoming. El sistema disposa d’una interfície que permet a les persones usuàries mantenir una conversa, el marc de la qual gira al voltant d’una narració sobre objectes, vegetals i animals com a entitats iguals. Les converses escrites són transformades en veu mitjançant TTS (Text to Speech) i transmeses a la planta amb el propòsit d’enfortir-la amb veus gairebé humanes.

Figura 30. Conversational implant 2018-2019 de Becoming
Font: web dels artistes.
Finalment, cal comentar que les interfícies de veu han despertat diverses inquietuds. D’una banda, ens faciliten l’accés i comunicació sense que hàgim de tocar o fer clic en una pantalla. Tanmateix, també afecten com i quina informació acaben retornant, especialment, pel que fa als continguts que obté d’internet. Quan som nosaltres que introduïm les cerques amb text a la pantalla d’un cercador, aquest darrer ens sol retornar múltiples resultats ordenats en diverses pàgines. Si bé està demostrat que la majoria d’usuaris no passen de la primera pàgina, la possibilitat de consultar altres resultats hi continua sent. En el cas de les interfícies per veu, es restringeix aquesta opció i nosaltres, com a persones usuàries, rebem la informació ja seleccionada, com si es tractés d’una elecció transparent.
Un àmbit addicional de preocupació envers les interfícies de veu és la capacitat d’escoltar-nos contínuament. Al subapartat 3.3 apareixen dos treballs artístics, HacKIT, de Rubez Chong, i Project Alias, de Bjørn Karmann. A més d’aquests projectes, hi ha iniciatives de codi obert com Mycroft, que, amb un esperit propositiu, volen garantir una bona experiència sense sacrificar la privacitat de les persones usuàries.